딥 러닝 deep learning
컴퓨터가 사람처럼 생각하고 배울 수 있도록 하는 인공지능(AI) 기술.
생각하는 컴퓨터의 등장
한 남자가 여자의 이름을 묻는다. “뭐라고 부르면 되죠? 이름이 있나요?” 여자는 잠시 뜸을 들인 뒤 대답한다. “음… 네, 사만다예요.” 남자는 궁금하다. 여자의 이름은 어떻게 생긴 것인지. “그 이름은 어디서 얻었나요?” 여자가 실토한다. “사실 방금 제가 혼자 지은 이름이에요.”
컴퓨터가 마치 사람처럼 배우고, 생각하는 세상이 오면 어떨까. 최근 개봉한 영화 ‘그녀(Her)’에 등장하는 '오에스원(OS1)’처럼 말이다. 주인공 테오도르가 OS1을 처음 컴퓨터에 설치한 이후 이름을 물어봤더니, OS1은 100분의 2초 만에 ‘아기 이름 짓는 법’이라는 책에 나오는 18만개의 이름 중 하나를 선택해 자신의 이름으로 삼는다. 발음할 때 소리가 좋다는 그럴듯한 이유까지 덧붙여서 말이다. 영화는 이 운영체제를 이렇게 소개한다.
“단순한 운영체제가 아닙니다. 또 하나의 의식입니다.”
최근 미국 실리콘밸리를 중심으로 한 기술 기업이 ‘딥러닝(Deep Learning)’ 기술에 손을 뻗고 있다. 딥러닝 기술은 컴퓨터가 마치 사람처럼 생각하고 배울 수 있도록 하는 기술을 말한다. 컴퓨터가 ‘또 하나의 의식’이 되는 셈이다.

인공신경망 이론을 기반으로
복잡한 비선형 문제를 기계가 스스로 학습해결 할 수 있도록 한다.
딥 러닝은 인간의 두뇌가 수많은 데이터 속에서 패턴을 발견한 뒤
사물을 구분하는 정보처리 방식을 모방해
컴퓨터가 사물을 분별하도록 기계를 학습시킨다.

딥 러닝 기술을 적용하면
사람이 모든 판단 기준을 정해주지 않아도
컴퓨터가 스스로 인지·추론·판단할 수 있게 된다.
음성·이미지 인식과 사진 분석 등에 광범위하게 활용된다.

[2] 생각하는 컴퓨터의 등장
한 남자가 여자의 이름을 묻는다.
“뭐라고 부르면 되죠? 이름이 있나요?”

여자는 잠시 뜸을 들인 뒤 대답한다.
“음… 네, 사만다예요.”

남자는 궁금하다. 여자의 이름은 어떻게 생긴 것인지.
“그 이름은 어디서 얻었나요?”
여자가 실토한다.
“사실 방금 제가 혼자 지은 이름이에요.”
컴퓨터가 마치 사람처럼 배우고, 생각하는 세상이 오면 어떨까.
최근 개봉한 영화 ‘그녀(Her)’에 등장하는 '오에스원(OS1)’처럼 말이다.

주인공 테오도르가 OS1을 처음 컴퓨터에 설치한 이후 이름을 물어봤더니,
OS1은 100분의 2초 만에 ‘아기 이름 짓는 법’이라는
책에 나오는 18만개의 이름 중 하나를 선택해 자신의 이름으로 삼는다.
발음할 때 소리가 좋다는 그럴듯한 이유까지 덧붙여서 말이다.
영화는 이 운영체제를 이렇게 소개한다.
“단순한 운영체제가 아닙니다. 또 하나의 의식입니다.”
최근 미국 실리콘밸리를 중심으로 한 기술 기업이 ‘딥러닝(Deep Learning)’ 기술에 손을 뻗고 있다.
딥러닝 기술은 컴퓨터가 마치 사람처럼 생각하고 배울 수 있도록 하는 기술을 말한다.
컴퓨터가 ‘또 하나의 의식’이 되는 셈이다.

영화 ‘그녀 Her’의 한 장면...관람객 평점 8.69 기자/평론가 평점 7.68

나는 지난 가을 이 영화를 보고 큰 충격을 받았다.
과연 그럴 수도 있겠다는 생각이 들었다.
아울러 영화의 끝에 이 Operating System의 의식이
아둔한(?) 인류를 버리고
우주 어디론가 떠나가 버린다는 설정도 그럴 듯 했다.
[3] 인공신경망 잇는 기계학습법
딥러닝은
사물이나 데이터를 군집화하거나 분류하는 데 사용하는 기술이다.
예를 들어 컴퓨터는 사진만으로 개와 고양이를 구분하지 못한다.

하지만 사람은 아주 쉽게 구분할 수 있다.

이를 위해 ‘기계학습(Machine Learning)’이라는 방법이 고안됐다.

많은 데이터를 컴퓨터에 입력하고 비슷한 것끼리 분류하도록 하는 기술이다.
저장된 개 사진과 비슷한 사진이 입력되면,
이를 개 사진이라고 컴퓨터가 분류하도록 한 것이다.

데이터를 어떻게 분류할 것인가를 놓고 이미 많은 기계학습 알고리즘이 등장했다.
‘의사결정나무’나 ‘베이지안망’, ‘서포트벡터머신(SVM)’, ‘인공신경망’ 등이 대표적이다.
이 중 딥러닝은 인공신경망의 후예다.

딥러닝은 인공신경망의 한계를 극복하기 위해 제안된 기계학습 방법이다.
딥러닝의 시작은 인공신경망 역사와 맞닿아 있기 때문이다.
1943년, 미국 일리노이 의대 정신과 부교수였던 워렌 맥컬록은
당시 의대 학생이었던 제리 레트빈과 월터 피츠와 함께
‘신경 활동에 내재한 개념들의 논리적 계산’이라는 제목의 논문을 발표한다.

‘신경 활동에 내재한 개념들의 논리적 계산’, 1943, 워렌 맥컬록
이들은 이 논문에서 신경망을 ‘이진 스위칭’ 소자가 복잡하게 연결된 네트워크로 모형화했다.
인공신경망을 개념화한 최초의 논문이다.
딥러닝이 처음 제안된 때는 인공신경망이 탄생한 지 40여년이 지난 1980년대다.
캘리포니아 대학 심리학자와 컴퓨터 관련 학자들의 신경망 연구를 요약한 <PDP>라는 저서가 등장하면서부터다.
딥러닝이 부활의 신호탄을 쏘아올리게 된 건 2004년이다.
제프리 힌튼 교수가 RBM이라는 새로운 딥러닝 기반의 학습 알고리즘을 제안하면서 주목을 받기 시작했다.
곧바로 드롭아웃이라는 알고리즘도 등장해 고질적으로 비판받는 과적합 등을 해결할 수 있게 됐다.

[4] 딥러닝의 두 갈래
딥러닝의 핵심은 분류를 통한 예측이다.
수많은 데이터 속에서 패턴을 발견해 인간이 사물을 구분하듯
컴퓨터가 데이터를 나눈다.

이 같은 분별 방식은 두 가지로 나뉜다.
‘지도 학습(supervised learning)’과
‘비지도 학습(unsupervised learning)’이다.


기존 기계학습 알고리즘은 대부분 지도 학습에 기초한다.
지도 학습 방식은 컴퓨터에 먼저 정보를 가르치는 방법이다.
예를 들어 사진을 주고 “이 사진은 고양이”라고 알려주는 식이다.
컴퓨터는 미리 학습된 결과를 바탕으로 고양이 사진을 구분하게 된다.

비지도 학습은 이 배움의 과정이 없다.
“이 사진이 고양이”라는 배움의 과정 없이
“이 사진이 고양이군”이라고 컴퓨터가 스스로 학습하게 된다.

지도 학습과 비교해 진보한 기술이며,
컴퓨터의 높은 연산 능력이 요구된다.
구글이 현재 비지도 학습 방식으로 유튜브에 등록된 동영상 중
고양이 동영상을 식별하는 딥러닝 기술을 개발한 상태다.

구글은 음성인식과 번역을 비롯해
로봇의 인공지능 시스템 개발에도 딥러닝 기술을 도입하고 있다.
대표적인 SNS 업체 페이스북은 딥러닝을
뉴스피드와 이미지 인식 분야에 적용하고 있다.

페이스북의 ‘딥페이스’ 동작 원리

유튜브 영상에서 고양이를 찾아내는 구글의 딥러닝 기술
[5] 딥러닝 좇는 구글·페이스북·MS·트위터
기술 기업이 딥러닝을 활용하는 분야는
주로 사진과 동영상, 음성 정보를 분류하는 쪽이다.
데이터의 양이 풍부하고, 정확성을 요구하기 때문이다.

우선 구글은
지난 2012년 앤드류 응 스탠포드대학교 교수와 함께
1만6천개의 컴퓨터와 10억개 이상의 신경네트워크를 구성해
심층신경네트워크(DNN)를 구현한 바 있다.
구글은 DNN 기술을 활용해 유튜브에 등록된 동영상 중 중에서
컴퓨터가 고양이를 영상을 인식하도록 하는 데 성공했다.

페이스북도
딥러닝 기술을 적용해 ‘딥페이스’라는 얼굴인식 알고리즘을 2014년 3월 개발했다.
이 알고리즘 개발을 주도한 조직이 얀 리쿤 교수가 이끌고 있는 인공지능 그룹이다.
페이스북은 딥페이스 알고리즘으로 전세계 이용자의 얼굴을 인식하고 있다.
인식 정확도는 97.25%로 인간 눈과 거의 차이가 없다.
인간의 눈은 97.53%의 정확도를 지닌 것으로 알려졌다.
페이스북은 이용자가 올린 이미지의 얼굴의 옆면만 봐도,
어떤 이용자인지 판별해낼 수 있다.

트위터가 인수한 매드비츠라는 업체는
페이스북 인공지능 연구소에서 일했던 클레멩 파라벳과 루이스 알렉산드레 에트자드 헤이다리,
얀 리쿤 뉴욕대학교 교수가 설립한 업체라는 점이 흥미롭다.
매드비츠도 딥러닝 기술을 사진 분석에 활용하는 업체다.

이미지기반 딥러닝 기술업체 매드비츠를 인수한 트위터
MS도
딥러닝 기술로 재미있는 연구를 진행하는 중이다.
MS는 2014년 7월 개최한 ‘MS 리서치 학술회의 2014’에서
개 품종을 컴퓨터가 분류하는 딥러닝 기술을 공개했다.
윈도우폰의 지능형 음성 비서 ‘코르타나’와 연동해
사용자가 스마트폰으로 찍은 개 사진을 보고 컴퓨터가 품종을 알려주는 기술이다.

MS 리서치는 이 기술에 ‘프로젝트 아담’이라는 이름을 붙였다.
프로젝트 아담의 바탕이 되는 개 사진은 약 1400만장 정도다.
MS는 구글이 소개한 DNN 기술과 비교해
약 50배나 더 빠른 분석 속도를 낸다고 설명했다.

[5] 네이버, 음성인식과 뉴스 분석에 딥러닝 기술 적용
국내에서도 딥러닝 연구가 활발하다. 네이버가 그 중심에 있다.
네이버는 음성인식을 비롯해
테스트 단계의 뉴스 요약, 이미지 분석에
딥러닝 기술을 적용하고 있다.
이미 네이버는 딥러닝 알고리즘으로
음성인식의 오류 확률을 25%나 개선했다.
네이버 딥러닝랩의 김정희 부장은
2013년에 열린 개발자 행사 ‘데뷰 2013’에서
딥러닝을 적용하기 전과 후를
“청동기 시대와 철기 시대와 같다”로 비유하기도 했다.
그만큼 성능 향상이 뚜렷했다는 의미다.
네이버는 야후의 썸리와 같은 뉴스 요약 서비스에도 딥러닝을 적용해 실험하고 있다.
기사에 제목이 있을 경우와 없을 경우를 분리해
기사를 정확히 요약해낼 수 있는 알고리즘을 개발하는 데 이 방식이 활용되고 있다.
2D 이미지 분석에 적용하기 위해 연구소 단위에서 실험 중이다.

네이버의 ‘링크’
2014년 6월 김범수 카카오 의장이 케이큐브를 통해 투자한 회사도
딥러닝 기술을 보유하고 있는 업체다.
다음도 딥러닝에 적잖은 투자를 이어가고 있다.
딥러닝 알고리즘을 활용하는 스타트업도 서서히 늘어나는 추세다.
2017년이면
전세계 컴퓨터의 10%가 데이터 처리가 아닌 딥러닝으로 학습하고 있을 것이라는 전망도 나왔다.
사람처럼 스스로 생각하는 컴퓨터. 또 하나의 의식 ‘사만다’의 등장이 머지않았다.

http://blog.daum.net/hongsy65/16793381
딥 러닝[1](영어: deep learning)은 여러 비선형 변환기법의 조합을 통해 높은 수준의 추상화(abstractions, 다량의 데이터나 복잡한 자료들 속에서 핵심적인 내용 또는 기능을 요약하는 작업)를 시도하는 기계학습(machine learning) 알고리즘의 집합[2] 으로 정의 되며, 큰틀에서 사람의 사고방식을 컴퓨터에게 가르치는 기계학습의 한 분야라고 이야기 할 수 있다.
어떠한 데이터가 있을 때 이를 컴퓨터가 알아 들을 수 있는 형태(예를 들어 이미지의 경우는 픽셀정보를 열벡터로 표현하는 등)로 표현(representation)하고 이를 학습에 적용하기 위해 많은 연구(어떻게 하면 더 좋은 표현기법을 만들고 또 어떻게 이것들을 학습할 모델을 만들지에 대한)가 진행되고 있으며, 이러한 노력의 결과로 deep neural networks, convolutional deep neural networks, deep belief networks와 같은 다양한 딥 러닝 기법들이 컴퓨터비젼, 음성인식, 자연어처리, 음성/신호처리 등의 분야에 적용되어 최첨단의 결과들을 보여주고 있다.
최근 이슈는 아무래도 스탠포드대학의 Andrew Ng과 Google이 함께한 딥 러닝 프로젝트인데, 2012년 16,000개의 컴퓨터 프로세스와 10억 개 이상의 neural networks 그리고 DNN(deep neural networks)을 이용하여 유튜브에 업로드 되어 있는 천만 개 넘는 비디오 중 고양이 인식에 성공한 내용[3] 으로 이 소프트웨어 프레임워크를 논문에서는 DistBelief로 언급하고 있다[4]. 이뿐만 아니라 Microsoft, Facebook[5] 등도 연구팀을 인수하거나 자체 개발팀을 운영하면서 인상적인 업적들을 만들어 내고 있다.
목차
[숨기기]딥 러닝의 역사[편집]
MIT가 2013년을 빛낼 10대 혁신기술 중 하나로 선정[6] 하고 가트너(Gartner, Inc.)가 2014 세계 IT 시장 10대 주요 예측[7] 에 포함시키는 등 최근들어 딥 러닝에 대한 관심이 높아지고 있지만 사실 딥 러닝 구조는 인공신경망(ANN, artificial neural networks)에 기반하여 설계된 개념으로 역사를 따지자면 최소 1980년 Kunihiko Fukushima에 의해 소개 된 Neocognitron[8] 까지 거슬러 올라가야 한다.
1989년에 Yann LeCun과 그의 동료들은 오류역전파 알고리즘(backpropagation algorithm)[9] 에 기반하여 우편물에 손으로 쓰여진 우편번호를 인식하는 deep neural networks를 소개[10] 했다. 알고리즘이 성공적으로 동작했음에도 불구하고, 신경망 학습에 소요되는 시간(10 개의 숫자를 인식하기 위해 학습하는 시간)이 거의 3일이 걸렸고 이것은 다른분야에 일반적으로 적용되기에는 비현실적인 것으로 여겨졌다.
많은 요소들이 느린 속도에 원인을 제공했는데, 그 중 하나는 1991년 Jürgen Schmidhuber의 제자였던 Sepp Hochreiter에 의해 분석된 vanishing gradient problem(지역최솟값에 머무르게 되는 원인)이었다[11][12]. 또한 불연속 시뮬레이션에서 초기 상태를 어떻게 선택하느냐에 따라 수렴이 안되고 진동 또는 발산하는 문제, 트레이닝셋에 너무 가깝게 맞추어 학습되는 과적응 문제, 원론적으로 생물학적 신경망과는 다르다는 이슈들이 끊임 없이 제기되면서 인공신경망은 관심에서 멀어졌고 90년대와 2000년대에는 SVM(support vector machine) 같은 조금은 단순한 기법(shallow learning이라 표현)들이 각광받게 된다.
본격적으로 딥 러닝이란 용어를 사용한 것은 2000년대 딥 러닝의 중흥기를 이끌어간다고 평가할 수 있는 Geoffrey Hinton[13] 과 Ruslan Salakhutdinov에 의해서이며, 기존 신경망의 과적응 문제를 해결하기 위해 이들은 unsupervised RBM(restricted Boltzmann machine)을 통해 학습시킬 앞먹임 신경망(Feedforward Neural Network)의 각 층을 효과적으로 사전훈련(pre-trainning)하여 과적응을 방지할 수 있는 수준의 initialize point를 잡았고, 이를 다시 supervised backpropagation를 사용[14] 하는 형태로 학습을 진행한다.
또한 가장 최근인 2013년, 신호처리학회인 ICASSP에서 RBM을 대체하여 과적응을 방지할 수 있는 Drop-out[15] 이라는 개념이 소개되면서 사전훈련 보다 훨씬 더 간단하고 강력한 형태로 과적응을 방지할 수 있게 되었다.
왜 다시 딥 러닝인가?[편집]
딥 러닝이 부활하게 된 이유는 크게 세 가지로 꼽힌다. 첫 번 째는 앞서 딥 러닝의 역사에서 언급한 바 있는 기존 인공신경망 모델의 단점이 극복되었다는 점이다. 그러나 과적응 문제만 해결되었다고 해서 느린 학습시간이 줄어드는 것은 아니다. 두 번 째 이유로, 여기에는 하드웨어의 발전이라는 또다른 요인이 존재 한다. 특히 강력한 GPU(graphics processing unit)들은 복잡한 매트릭스와 벡터 계산이 혼재해 있는 경우 몇 주 걸리던 작업을 며칠 사이로 줄이는 등 최고의 성능(GeForce GTX Titan의 경우 계산이 가능한 CUDA core가 무려 2688개 존재[16])을 발휘하고 있다. 마지막으로 언급하지만 가장 중요한 세 번 째 이유로 Big Data를 들 수 있다. 대량으로 쏟아져 나오는 데이터들, 그리고 그것들을 수집하기 위한 노력 특히 SNS 사용자들에 의해 생산되는 다량의 자료와 태그정보들 모두가 종합되고 분석 되어 학습에 이용될 수 있다. - 인공신경망의 학습에 사용되는 트레이닝벡터는 이름이 붙어 있는(labeled) 데이터여야 하는데(supervised learning의 경우) 대량의 트레이닝셋 모두에 label을 달아주는 일은 불가능한 일이다. 이런 이유로 초기 학습에 사용되는 일부 데이터에 대해서만 지도학습(supervised learning)을 수행하고 나머지 트레이닝셋에 대해서는 비지도학습(unsupervised learning)을 진행하며, 학습된 결과는 기존 학습의 결과와 앞서 분석된 메타태그 정보들을 종합하여 인식기가 완성 된다.
딥 러닝의 부활 이후 다양한 분야, 특히 자동 음성 인식(ASR, automatic speech recognition)과 컴퓨터비전 분야에서 최고수준의 성능을 보여주고 있으며 이들은 보통 딥 러닝의 새로운 응용들의 지속적인 성능 향상을 위해 만들어진 TIMIT(Texas Instruments와 MIT가 제작한 음성 Database), MNIST(이미지 클러스터링을 위한 hand-written 숫자 이미지 database로 National Institute of Standards and Technology가 제작) 등의 데이터베이스를 사용했다. 최근에는 convolution neural networks 기반의 딥 러닝 알고리즘이 가장 뛰어난 성능을 발휘하고 있으나, 안타깝게도 컴퓨터비전 쪽 과제보다는 음성인식 쪽에서 많은 발전을 이루고 있다.
알고리즘[편집]
다양한 종류의 심층 신경망 구조가 존재하지만, 대부분의 경우 대표적인 몇 가지 구조들에서 파생된 것이다. 그렇지만 여러 종류의 구조들의 성능을 동시에 비교하는 것이 항상 가능한 것은 아닌데, 그 이유는 특정 구조들의 경우 주어진 데이터 집합에 적합하도록 구현되지 않은 경우도 있기 때문이다.
심층 신경망(Deep Neural Network, DNN)[편집]
심층 신경망(Deep Neural Network, DNN)은 입력 계층(input layer)과 출력 계층(output layer) 사이에 복수개의 은닉 계층(hidden layer)들로 이뤄진 인공신경망(Artificial Neural Network, ANN)이다.[17][18] 심층 신경망은 일반적인 인공신경망과 마찬가지로 복잡한 비선형 관계(non-linear relationship)들을 모델링할 수 있다. 예를 들어, 사물 식별 모델을 위한 심층 신경망 구조에서는 각 객체가 이미지 기본 요소들의 계층적 구성으로 표현될 수 있다.[19] 이때, 추가 계층들은 점진적으로 모여진 하위 계층들의 특징들을 규합시킬 수 있다. 심층 신경망의 이러한 특징은, 비슷하게 수행된 인공신경망에 비해 더 적은 수의 유닛(unit, node)들 만으로도 복잡한 데이터를 모델링할 수 있게 해준다.[17]
이전의 심층 신경망들은 보통 앞먹임 신경망으로 설계되어 왔지만, 최근의 연구들은 심층 학습 구조들을 순환 신경망(Recurrent Neural Network, RNN)에 성공적으로 적용했다. 일례로 언어 모델링(language modeling) 분야에 심층 신경망 구조를 적용한 사례 등이 있다.[20] 합성곱 신경망(Convolutional Neural Network, CNN)의 경우에는 컴퓨터 비전(computer vision) 분야에서 잘 적용되었을 뿐만 아니라, 각각의 성공적인 적용 사례에 대한 문서화 또한 잘 되어 있다.[21] 더욱 최근에는 합성곱 신경망이 자동 음성인식 서비스(Automatic Response Service, ARS)를 위한 음향 모델링(acoustic modeling) 분야에 적용되었으며, 기존의 모델들 보다 더욱 성공적으로 적용되었다는 평가를 받고 있다.[22]
심층 신경망은 표준 오류역전파 알고리즘을 가지고 구별되게 학습될 수 있다. 이때, 가중치(weight)들은 아래의 등식을 이용한 확률적 경사 하강법(stochastic gradient descent)을 통하여 갱신될 수 있다.
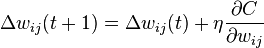
여기서, 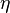 는 학습률(learning rate)을 의미하며,
는 학습률(learning rate)을 의미하며,  는 비용함수(cost function)를 의미한다. 비용함수의 선택은 학습의 형태(지도 학습, 자율 학습 (기계 학습), 강화 학습 등)와 활성화함수(activation function)같은 요인들에 의해서 결정된다. 예를 들면, 다중 클래스 분류 문제(multiclass classification problem)에 지도 학습을 수행할 때, 일반적으로 활성화함수와 비용함수는 각각 softmax 함수와 교차 엔트로피 함수(cross entropy function)로 결정된다. softmax 함수는
는 비용함수(cost function)를 의미한다. 비용함수의 선택은 학습의 형태(지도 학습, 자율 학습 (기계 학습), 강화 학습 등)와 활성화함수(activation function)같은 요인들에 의해서 결정된다. 예를 들면, 다중 클래스 분류 문제(multiclass classification problem)에 지도 학습을 수행할 때, 일반적으로 활성화함수와 비용함수는 각각 softmax 함수와 교차 엔트로피 함수(cross entropy function)로 결정된다. softmax 함수는 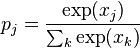 로 정의된다, 이때,
로 정의된다, 이때, 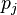 는 클래스 확률(class probability)을 나타내며,
는 클래스 확률(class probability)을 나타내며, 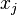 와
와 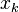 는 각각 유닛
는 각각 유닛  로의 전체 입력(total input)과 유닛
로의 전체 입력(total input)과 유닛  로의 전체 입력을 나타낸다. 교차 엔트로피는
로의 전체 입력을 나타낸다. 교차 엔트로피는 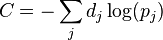 로 정의된다, 이때,
로 정의된다, 이때,  는 출력 유닛 에 대한 목표 확률(target probability)을 나타내며, 는 해당 활성화함수를 적용한 이후의 에 대한 확률 출력(probability output)이다.[23]
는 출력 유닛 에 대한 목표 확률(target probability)을 나타내며, 는 해당 활성화함수를 적용한 이후의 에 대한 확률 출력(probability output)이다.[23]
심층 신경망의 문제점[편집]
기존의 인공신경망과 같이, 심층 신경망 또한 나이브(naive)한 방식으로 학습될 경우 많은 문제들이 발생할 수 있다. 그 중 과적응(overfitting)과 높은 시간 복잡도가 흔히 발생하는 문제들이다.
심층 신경망이 과적응에 취약한 이유는 추가된 계층들이 학습 데이터의 rare dependency의 모형화가 가능토록 해주기 때문이다. 과적응을 극복하기 위해서 weight decay (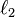 –regularization) 또는 sparsity (
–regularization) 또는 sparsity ( –regularization) 와 같은 regularization 방법들이 사용될 수 있다.[24] 그리고 최근에 들어서는 심층 신경망에 적용되고 있는 regularization 방법 중 하나로 dropout regularization이 등장했다. dropout regularization에서는 학습 도중 은닉 계층들의 몇몇 유닛들이 임의로 생략된다. 이러한 방법은 학습 데이터(training data)에서 발생할 수 있는 rare dependency를 해결하는데 도움을 준다.[25]
–regularization) 와 같은 regularization 방법들이 사용될 수 있다.[24] 그리고 최근에 들어서는 심층 신경망에 적용되고 있는 regularization 방법 중 하나로 dropout regularization이 등장했다. dropout regularization에서는 학습 도중 은닉 계층들의 몇몇 유닛들이 임의로 생략된다. 이러한 방법은 학습 데이터(training data)에서 발생할 수 있는 rare dependency를 해결하는데 도움을 준다.[25]
오차역전파법과 경사 하강법은 구현의 용이함과 국지적 최적화(local optima)에 잘 도달한다는 특성으로 인해 다른 방법들에 비해 선호되어온 방법들이다. 그러나 이 방법들은 심층 신경망을 학습 시킬 때 시간 복잡도가 매우 높다. 심층 신경망을 학습시킬 때에는 크기(계층의 수 와 계층 당 유닛 수), 학습률, 초기 가중치 등 많은 매개변수(parameter)들이 고려되어야 한다. 하지만 최적의 매개변수들을 찾기 위해 매개변수 공간 전부를 확인하는 것은 계산에 필요한 시간과 자원의 제약으로 인해 불가능하다. 시간 복잡도를 해결하기 위해, mini-batching(여러 학습 예제들의 경사를 동시에 계산)과 같은 다양한 '묘책’들이 등장하였다.[26] 또한, 행렬 및 벡터 계산에 특화된 GPU는 많은 처리량을 바탕으로 두드러지는 학습 속도 향상을 보여주었다.[18]
합성곱 신경망(Convolutional Neural Network, CNN)[편집]
합성곱 신경망(Convolutional Neural Network, CNN)은 최소한의 전처리(preprocess)를 사용하도록 설계된 다계층 퍼셉트론(multilayer perceptrons)의 한 종류이다. CNN은 하나 또는 여러개의 합성곱 계층과 그 위에 올려진 일반적인 인공 신경망 계층들로 이루어져 있으며, 가중치와 통합 계층(pooling layer)들을 추가로 활용한다. 이러한 구조 덕분에 CNN은 2차원 구조의 입력 데이터를 충분히 활용할 수 있다. 다른 딥 러닝 구조들과 비교해서, CNN은 영상, 음성 분야 모두에서 좋은 성능을 보여준다. CNN은 또한 표준 역전달을 통해 훈련될 수 있다. CNN은 다른 피드포워드 인공신경망 기법들보다 쉽게 훈련되는 편이고 적은 수의 매개변수를 사용한다는 이점이 있다. 최근 딥 러닝에서는 합성곱 심층 신뢰 신경망 (Convolutional Deep Belief Network, CDBN) 가 개발되었는데, 기존 CNN과 구조적으로 매우 비슷해서, 그림의 2차원 구조를 잘 이용할 수 있으며 그와 동시에 심층 신뢰 신경망 (Deep Belief Network, DBN)에서의 선훈련에 의한 장점도 취할 수 있다. CDBN은 다양한 영상과 신호 처리 기법에 사용될 수 있는 일반적인 구조를 제공하며 CIFAR[27] 와 같은 표준 이미지 데이터에 대한 여러 벤치마크 결과에 사용되고 있다.
순환 신경망(Recurrent Neural Network, RNN)[편집]
순환 신경망은 인공신경망을 구성하는 유닛 사이의 연결이 Directed cycle을 구성하는 신경망을 말한다. 순환 신경망은 앞먹임 신경망과 달리, 임의의 입력을 처리하기 위해 신경망 내부의 메모리를 활용할 수 있다. 이러한 특성에 의해 순환 신경망은 필기체 인식(Handwriting recognition)과 같은 분야에 활용되고 있고, 높은 인식률을 나타낸다.[28] 순환 신경망을 구성할 수 있는 구조에는 여러가지 방식이 사용되고 있다. 완전 순환망(Fully Recurrent Network), Hopfield Network, Elman Network, Echo state network(ESN), Long short term memory network(LSTM), Bi-directional RNN, Continuous-time RNN(CTRNN), Hierarchical RNN, Second Order RNN 등이 대표적인 예이다. 순환 신경망을 훈련(Training)시키기 위해 대표적으로 경사 하강법, Hessian Free Optimization, Global Optimization Methods 방식이 쓰이고 있다. 하지만 순환 신경망은 많은 수의 뉴런 유닛이나 많은 수의 입력 유닛이 있는 경우에 훈련이 쉽지 않은 스케일링 이슈를 가지고있다.
제한 볼츠만 머신 (Restricted Boltzmann Machine, RBM)[편집]
볼츠만 머신에서, 층간 연결을 없앤 형태의 모델이다. 층간 연결을 없애면, 머신은 가시 유닛(Visible Unit)과 은닉 유닛(Hidden Unit)으로 이루어진 무방향 이분 그래프 형태의 모양이 된다. 결론적으로 모델의 층간 연결을 없앰으로써, 얻는 이점으로 뉴럴 네트워크는 깊어질 수 있었다. 가장 큰 이점은 가시 유닛이 관찰되고 고정(Clamped)되었을 때 은닉 유닛을 추론(Inference) 하는 MCMC 과정이 단 한 번에 끝난다는 것이다. RBM는 확률모델의 계산이 Intractable 하기 때문에, 학습시 근사법인 MCMC 나 또는 제프리 힌튼 교수가 발견한 CD(Contrastive Divergence) 를 사용하는데, RBM의 모델의 간단함에서 오는 추론에 대한 이점은 샘플링 근간의 학습법이 실용적인 문제에 적용되는데 기여했다. 자세한 학습 방법은 아래에 설명 되어 있다.
RBM은 DBN의 기본 뼈대가 된다, RBM을 쌓아올리면서(Stacking), Greedy하게 학습함으로써, DBN을 완성한다. DBN을 아는 사람은 기본적으로 RBM은 무방향이기에, RBM이 방향성 있는 모델인 DBN이 되는지 의아할 것이다. 이는 제프리 힌튼 의 제자인 Teh, Y. W 의 우연 발견적인 연구 성과인데, 원래 힌튼 교수는 Graphical Model 이 방향성을 가질 때 생기는 Explaining Away 효과 때문에 학습이 매우 어려워 연구를 무방향성 모델로 선회했다가, RBM을 쌓으면, 다층 RBM이 되는 것이 아니라, DBN과 비슷해진다는 사실을 발견하게 된다. 이 발견은 DBN학습을 단순히 여러 개의 RBM 학습으로 환원시킴으로써(앞서서 얘기했듯이 RBM은 학습이 어렵지 않다) 어려운 DBN 학습의 복잡도를 층의 갯수에 비례하는 복잡도로 낮추었다. 이는 선행학습(Pre-training) 과 미조정(Fine-tuning) 의 새로운 학습 패러다임으로 발전하게 된다.
RBM 훈련 과정에서의 가중치 갱신은, 다음의 식을 기반으로 경사 하강법을 통해 이루어진다.  여기서
여기서 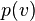 는 다음의 식으로 주어지는 가시 벡터의 확률을 나타내고,
는 다음의 식으로 주어지는 가시 벡터의 확률을 나타내고, 
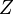 는 정규화를 위해 사용되는 분배함수(partition function)이며,
는 정규화를 위해 사용되는 분배함수(partition function)이며, 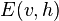 는 신경망의 상태(state)에 부여되는 에너지 함수이다. 에너지가 낮을수록 해당 신경망이 더 적합한 상태임을 의미한다. 기울기
는 신경망의 상태(state)에 부여되는 에너지 함수이다. 에너지가 낮을수록 해당 신경망이 더 적합한 상태임을 의미한다. 기울기  는 좀 더 간단하게
는 좀 더 간단하게  로 표현이 되는데 이 때
로 표현이 되는데 이 때 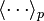 는 분포
는 분포  에 관한 평균을 의미한다.
에 관한 평균을 의미한다.  을 샘플링 하려면 alternating Gibbs sampling을 매우 많이 반복해야 하기 때문에 CD에서는 alternating Gibbs sampling을
을 샘플링 하려면 alternating Gibbs sampling을 매우 많이 반복해야 하기 때문에 CD에서는 alternating Gibbs sampling을  회만 반복한다.(실험을 통해
회만 반복한다.(실험을 통해 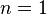 일 경우에도 충분한 성능이 나온다고 알려져 있다). 회 반복 후 샘플링 된 데이터가 를 대신한다. CD 수행 과정은 다음과 같다:
일 경우에도 충분한 성능이 나온다고 알려져 있다). 회 반복 후 샘플링 된 데이터가 를 대신한다. CD 수행 과정은 다음과 같다:
- 가시 유닛들을 훈련 벡터로 초기화 한다.
- 다음의 가시 유닛들이 주어지면 은닉 유닛들을 모두 동시에 갱신한다:
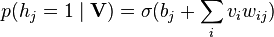 .
.  는 시그모이드 함수(sigmoid function)를 의미하며,
는 시그모이드 함수(sigmoid function)를 의미하며,  는
는  의 편향이다.
의 편향이다. - 다음의 은닉 유닛들이 주어지면 가시 유닛들을 모두 동시에 갱신한다:
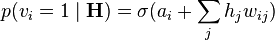 .
. 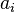 는
는 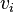 의 편향이다. 이 부분을 "복원(reconstruction)"이라고 부른다.
의 편향이다. 이 부분을 "복원(reconstruction)"이라고 부른다. - 복원된 가시 유닛들이 주어지면 2 에서 쓰인 식을 이용하여 은닉 유닛들을 모두 동시에 다시 갱신한다.
- 다음과 같이 가중치를 갱신한다:
 .
.
심층 신뢰 신경망 (Deep Belief Network, DBN)[편집]
심층 신뢰 신경망(Deep Belief Network, DBN)이란 기계학습에서 사용되는 그래프 생성 모형(generative graphical model)으로, 딥 러닝에서는 잠재변수(latent variable)의 다중계층으로 이루어진 심층 신경망을 의미한다. 계층 간에는 연결이 있지만 계층 내의 유닛 간에는 연결이 없다는 특징이 있다.
DBN은 생성 모형이라는 특성상 선행학습에 사용될 수 있고, 선행학습을 통해 초기 가중치를 학습한 후 역전파 혹은 다른 판별 알고리즘을 통해 가중치의 미조정을 할 수 있다. 이러한 특성은 훈련용 데이터가 적을 때 굉장히 유용한데, 이는 훈련용 데이터가 적을수록 가중치의 초기값이 결과적인 모델에 끼치는 영향이 세지기 때문이다. 선행학습된 가중치 초기값은 임의로 설정된 가중치 초기값에 비해 최적의 가중치에 가깝게 되고 이는 미조정 단계의 성능과 속도향상을 가능케 한다.
DBN은 비지도 방식으로 계층마다 학습을 진행하는데 이때 각각의 계층은 보통 RBM의 형태를 띄고 있다. RBM들을 쌓아 올리면서 DBN을 훈련시키는 방법에 대한 설명은 아래에 제공 되어 있다. RBM은 에너지 기반의 생성 모형으로 가시 유닛과 은닉 유닛으로 이루어진 무방향 이분 그래프 형태이다. 가시 유닛들과 은닉 유닛들 사이에만 연결이 존재한다.
RBM이 훈련되고 나면 다른 RBM이 그 위에 쌓아 올려짐으로써 다중 계층 모형을 형성한다. RBM이 쌓아 올려질 때마다, 이미 훈련된 RBM의 최상위 계층이 새로 쌓이는 RBM의 입력으로 쓰인다. 이 입력을 이용하여 새 RBM이 훈련되고, 원하는 만큼의 계층이 쌓일 때까지 해당 과정이 반복된다.
실험결과에 따르면, CD의 최대가능도 근사가 굉장히 투박함에도 불구하고, 심층 신경망 구조를 학습하기에는 충분히 효과적인 방식이라고 한다.
심층 Q-네트워크(Deep Q-Networks)[편집]
2015년 2월, 강화 학습을 위한 가장 최신 딥 러닝 모델이 네이처에 소개되었다.[29]
응용[편집]
자동 음성 인식[편집]
아래 표는 TIMIT 데이터에 대한 자동 음성 인식 결과를 보여준다. 이 데이터셋은 딥 러닝의 초창기 평가를 위한 일반적인 데이터로서, 미국의 8가지 방언을 사용하는 총 630명의 사람이 읽은 10가지 문장으로 이루어져 있다.[30] 데이터의 크기가 작기 때문에 다양한 설정을 효과적으로 적용할 수 있다. 더 중요한 점은 TIMIT에서 음소 순서 인식(phone-sequence recognition)을 고려한다는 점이다. 따라서, 단어 순서 인식(word-sequence recognition)과는 달리 아주 약한 "언어모델"을 허용하고 음성 인식에서의 음향 모델 측면을 더 쉽게 분석할 수 있다. 2009 ~ 2010년 무렵, 크고 작은 범위의 음성인식에 대한 딥 러닝 기술 활용을 위해서 많은 투자가 있었는데, Li Deng과 그의 동료들은 TIMIT에서의 GMM 과 DNN 모델을 비교하는 실험을 수행하였다.[31][32] 결국 그들은 음성인식에서의 딥 러닝 활용에 있어서 가장 앞서나가게 되었다. 이 분석은 먼저 식별적 DNN과 발생적 모델 사이의 성능 비교(1.5% 이하의 오차율)로 수행되었다. 아래 표에 나타난 오차율은 앞에서 말한 초창기 실험을 포함하여 과거 20 여 년 간 수행된 실험들의 음소 오차율(Phone error rate)을 요약한 것이다.
| 방식 | PER (%) |
|---|---|
| Randomly Initialized RNN | 26.1 |
| Bayesian Triphone GMM-HMM | 25.6 |
| Hidden Trajectory (Generative) Model | 24.8 |
| Monophone Randomly Initialized DNN | 23.4 |
| Monophone DBN-DNN | 22.4 |
| Triphone GMM-HMM with BMMI Training | 21.7 |
| Monophone DBN-DNN on fbank | 20.7 |
| Convolutional DNN[33] | 20.0 |
| Convolutional DNN w. Heterogeneous Pooling | 18.7 |
| Ensemble DNN/CNN/RNN[34] | 18.2 |
| Bidirectional LSTM | 17.9 |
TIMIT로부터 대량 어휘 음성인식(large vocabulary speech recognition)으로의 딥 러닝의 확장은 2010년 산업계 연구자들에 의해 성공적으로 수행되었다.[35][36] 자동 음성 인식 분야의 2014년 10월까지의 최신 동향은 마이크로소프트 리서치의 책 에 잘 정리되어있다.[37] 또한 자동 음성인식과 관련된 배경 지식과 다양한 기계학습 패러다임의 영향을 잘 정리한 글을 참고할 수 있다.[38] 대용량 자동 음성인식은 최근 딥 러닝의 역사에서 산업계와 학계를 모두 아우르는 처음이자 가장 성공적인 케이스라고 할 수 있다. 2010년부터 2014년까지, 신호처리와 음성인식에 대한 주요 학술회의인 IEEE-ICASSP 와 Interspeech는 음성인식을 위한 딥 러닝 분야의 합격 논문 개수에 있어서 거의 기하급수적인 성장을 보여주었다. 더 중요한 것은, 현재 모든 주요 상업 음성인식 시스템(MS 코타나, 스카이프 번역기, 구글 나우, 애플 시리 등등)이 딥 러닝 기법에 기반하고있다는 점이다.[39][40][41] 뉘앙스 커뮤니케이션즈의 CTO의 최근 인터뷰도 참고할만하다.[42]
영상 인식[편집]
일반적으로 이미지 분류를 위한 평가 데이터로서 MNIST 데이터베이스 데이터가 이용된다. MNIST는 손으로 쓴 숫자들로 구성되어 있으며, 60000개의 학습 예제들과 10000개의 테스트 예제들을 포함한다. TIMIT와 유사하게, 적은 용량의 MNIST 데이터는 복수의 테스트 환경설정이 가능하게 해준다. MNIST 데이터에 대한 종합적인 결과들을 [123]에서 확인할 수 있다. 현재까지 MNIST 데이터에 대한 가장 우수한 결과는 Ciresan 등이 작성한 [43] 에서 달성되었으며, 오차율 0.23%를 기록했다.
Geoff Hinton과 그의 제자들은 2012년 가을에 대규모 ImageNet 대회에서 당시 최신 기계 학습 방법들의 성능을 훌쩍 뛰어넘는 결과를 보여주며 우승하였다. 이로 인해 컴퓨터 비전의 주요 분야인 영상 인식 및 사물 인식 분야에서의 딥 러닝의 중요성이 대두되었다. 그 당시, 대규모 음성인식에 딥 러닝이 상당히 잘 작동한다는 것을 알고 있었던 그들은, 20년 전에 고안된 심층 합성곱 신경망 구조를 대규모 작업에 맞도록 대규모로 사용하였다. 2013년부터 2014년에 이르기까지, 딥 러닝을 이용한 ImageNet 과제 결과의 오차율은 대규모 음성인식 분야와 추세를 같이하며 빠르게 줄어나갔다.
자동 음성인식 분야의 자동 음성 번역 및 이해 분야로의 확장과 마찬가지로, 이미지 분류 분야는 자동 영상 캡션닝(captioning)이라는 더욱 도전적인 분야로 확장되었다. 자동 영상 캡셔닝은 딥 러닝을 핵심 기반 기술로 사용하는 분야이다.[44] [45] [46] [47]
적용 사례로는 360°카메라 화면을 이해할 수 있도록 딥 러닝을 통해 학습된 자동차 탑재용 컴퓨터 등이 있다.[48]
자연어 처리[편집]
2000년대 초부터 인공신경망은 언어 모형을 구현하기 위해 사용되어 왔다. 이 분야에서의 핵심 기법은 negative sampling과 단어 표현(word embedding)이다. word2vec과 같은 단어 표현은 데이터집합으로 주어진 단어들 사이의 관계를 학습하는 인공신경망을 이용하여 단어를 벡터 공간 상에 나타내는 것이라고 할 수 있다. 단어표현을 재귀 신경망(recursive neural network)의 입력 계층으로 이용하면 해당 신경망이 compositional vector grammar를 통해 문장과 구(phrase)를 분석하도록 학습시킬 수 있다. 이 compositional vector grammar는 재귀 신경망으로 구현된 probabilistic context free grammar (PCFG) 라고 할 수 있다. 단어표현을 기반으로 구성된 Recursive autoencoder는 문장 간의 유사도 판단과 의역 탐지를 하도록 훈련이 가능하다. 이러한 심층 인공신경망 구조들은 자동 번역(machine translation), 감정 분석(sentiment analysis), 정보 검색(information retrieval)을 비롯한 다양한 자연언어처리 관련 연구에서 최첨단 기술로서 쓰이고 있다.
약물 발견과 독성학[편집]
제약 산업에서 많은 수의 약들은 시장에 출시되지 못한다. 이렇게 실패하는 이유중 하나는 생각한 만큼의 효험을 보이지 못하거나, 예상치 못한 다른 작용을 일으키기 때문이다. 이를 해결하기 위해 2012년 George Dahl의 팀은 다중 DNN을 약의 효험을 예측하는 데에 활용하여 "Merck Molecular Activity Challenge"에 우승하였고[49][50], 2014년 Sepp Hochreiter의 팀은 예상치 못한 다른 작용을 사전에 탐지하기 위해 딥 러닝을 활용하여 "Tox21 Data Challenge"에서 우승하였다..[51][52] 이러한 성공은 딥 러닝이 약학에 있어 가상 실험 방법(Virtual Screening Method)에 적합함을 보여준다.[53][54] 현재 많은 수의 연구자들이 여러가지 데이터를 조합하여 약물을 발견하는 데에 딥 러닝을 활용하고 있다.[55]
고객 관계 관리[편집]
최근 직접 마케팅 기획, 고객 관계 관리 자동화를 위한 수단 적합성 산출 등에 직접적으로 심층 강화 학습을 활용하여 성공하는 사례들이 알려지고 있다. 인공 신경망은 RFM으로 정의된 고객들에 대한 활용 가능한 마케팅 활동의 값을 예측할 때 사용되었다. 예측된 함수는 고객 생명 주기 값(customer lifetime value, CLV)으로 변환되어 사용되었다.[56]
딥 러닝과 인간 두뇌[편집]
딥 러닝은 인지신경과학자(Cognitive neuroscientist)들이 1990년대 초에 제안한 뇌 발달(Brain development)과 밀접한 관련이 있다.[57][58][59] 이러한 발달 관점의 이론들이 도입되면서, 순수한 전산 기반의 딥 러닝 모델들을 위한 기술적인 기반도 마련되었다. 발달 이론에서는 신경발달요인(Nerve growth factor)의 물결과 같은 뇌에서의 다양한 학습 역학이 결국은 서로 연관된 신경망들의 자기조직화를 도와준다는 특징이 있다. 이는 나중에 전산 기반의 딥 러닝 모델에서도 활용되어서, 인공신경망의 계층적인 필터 구조(각 동작 환경에서 필요한 정보만 걸러내는 다중 계층 구조)가 실제 뇌의 피질과 유사해보이게 되었다. 이러한 과정을 통해 자기조직적인 변환기의 계층구조가 만들어지고 각 환경에 맞도록 조율된다. 1995년에 뉴욕 타임스에서는 다음과 같이 말하였다. "...유아의 두뇌는 영양적인 요인의 영향으로 스스로 조직화되는 것 같다... 뇌에서 한 층의 조직이 먼저 성숙되고 다른 부분과 순차적으로 연결되는 방식으로 전체 뇌가 성숙될 때 까지 반복된다." [60]
인간의 인식 발달 및 진화와 관련하여 딥 러닝의 중요성은 많은 과학자들의 관심을 끌고 있다. 가까운 영장류 동물들과 인간이 차별화되는 부분 중 하나는 바로 발달 시기이다.[61] 다른 영장류 동물들의 뇌가 출산 전에 거의 완성되는 반면에, 인간의 뇌는 비교적 출산 후에도 계속 발달하는 편이다. 그래서 인간의 경우 뇌가 발달되는 중요한 시기 동안 세상 밖의 훨씬 더 복잡한 경험에 노출될 수 있다. 이러한 현상은 인간이 다른 동물들에 비하여 빠르게 변화하는 환경에 더 잘 적응할 수 있도록 만든다. 이러한 변화의 정도는 대뇌 피질 발달에 반영되기도 하고, 또한 두뇌의 자기조직화 시기에 자극적인 환경으로부터의 정보 추출에 변화를 준다. 물론, 이러한 유연성은 인간이 다른 동물들에 비해 긴 미성숙기(보호자에게 도움을 받고 훈련을 받아야 하는 의존적인 시기)를 가지게 된 원인이기도 하다. 딥 러닝의 이런 이론들은 결국 인간 진화의 기본적인 조건으로서 문화와 인식의 공진화를 보여준다.
영리 활동[편집]
딥 러닝은 종종 강인공지능의 현실화를 향한 발걸음으로 묘사되기도 하기 때문에 많은 기관에서 딥 러닝의 활용에 관심을 보이고 있다. 2013년 3월, Geoffrey Hinton과 두 명의 제자(Alex Krizhevsky and Ilya Sutskever)가 구글에 채용되었다. 이들은 구글의 기존 기계 학습 제품들을 향상시키고 구글이 가지고있는 데이터를 더 잘 활용할 수 있도록 돕는 일을 할 것이다. 구글은 또한 Hinton의 회사 DNNresearch를 인수하였다. 2013년 12월에는 페이스북이 캘리포니아, 런던, 뉴욕에서 운영될 인공지능 연구실의 수장으로 Yann LeCun을 채용했다고 발표하였다. 이 인공지능 연구실에서는 딥 러닝 기법들을 연구 하여 페이스북의 사진에 자동으로 사람의 이름을 연결시키는 등의 기능을 구현할 예정이다.[62] 2014년, 구글은 영국의 스타트업기업인 DeepMind Technologies를 인수하였다. DeepMind에서는 화면의 정보만을 가지고 비디오 게임을 어떻게 플레이하는지를 스스로 학습하는 시스템을 개발하였다. 바이두 는 Andrew Ng을 그들의 새로운 실리콘밸리 딥 러닝 연구실의 수장으로 채용하였다.
부정적 시각과 코멘트[편집]
딥 러닝에 대한 부정적 시각중 하나로 딥 러닝에 사용되는 방법들의 이론적인 뒷받침이 빈약하다는 것이 있다. 대부분의 딥 러닝 알고리즘은 경사 하강법에 기초를 두고 있다. 그런데 경사 하강법 자체는 이론적으로 이해가 잘 되었지만, 이와 함께 사용하는 다른 알고리즘은 이론적인 검증이 빈약하다. 그러한 알고리즘 중 하나인 contrastive divergence는 이 알고리즘이 실제로 정말 수렴하는지, 수렴한다면 얼마나 빠르게 수렴하는지에 대한 부분이 현재 분명하게 증명되지 않았다. 이와 같이, 딥 러닝에 사용되는 방법들은 이론적이기 보다는 경험적으로 검증된 방법들을 사용하기 때문에 종종 블랙박스로 이해되기도 한다.
또다른 사람들은 보통 사람들이 딥 러닝을 모든 것을 해결해주는 솔루션으로 바라보는 것에 대해 딥 러닝은 유일한 솔루션이 아니고, 강한 인공 지능을 실현하는 데에 한 걸음 더 다가갈 수 있게 해주는 것으로 봐야한다고 주장한다. 딥 러닝을 모든 것을 해결해주는 솔루션으로 보기에는 기능적으로 여전히 부족한 점이 많기 때문이다. 심리학자인 Gary Marcus는 다음과 같이 말했다.
"현실적으로, 딥 러닝은 지능형 기계를 구축하는 것의 일부분에 불과합니다. 딥 러닝에 쓰이는 테크닉들은 인과 관계를 나타내는 능력이 부족하고 (...) 논리적 추론을 하는 것에 확실한 방법을 가지고있지 않습니다. 그리고 이 방법들은 어떤 물체가 무엇인지, 용도가 무엇인지 등과 같은 추상적인 정보를 인식하는 데에 오랜 시간이 걸립니다. 왓슨과 같이 현재 가장 강력한 인공지능 시스템은 (...) 딥 러닝을 복잡한 여러 개의 테크닉 중 단지 한 부분을 위해 사용하고 있습니다." [63]
'베리칩·1 > 베리칩·1' 카테고리의 다른 글
| [스크랩] 두 번째 짐승의 표 (2013년 9월 26일) (0) | 2016.04.08 |
|---|---|
| [스크랩] 송명희시인의 대 환란 소설 "표" - 3 (부르심을 입은 사람들) (0) | 2016.04.03 |
| [스크랩] (CBS New York) 재소자의 위치추적을 위해 GPS 이식을 제안 (0) | 2016.03.26 |
| “뇌에 ‘자기장’을 쏘아 종교·사상 바꿀 수 있다?! (0) | 2016.03.19 |
| [스크랩] 무선 신호로 몸 안에서 약을 투여하는 칩(베리칩)이 개발되었다. (펌) (0) | 2016.03.11 |